
In my SANS SEC 497 practical OSEC course, one of the topics we cover is dealing with large data sets, particularly focusing on indexing. An index works very similar to the way an index in a book works. Imagine I gave you a 1200-page book of world history and asked you to find every page that mentioned Napoleon. This task could take you a week if you have to read through the entire book and jot down any page that mentions Napoleon, or it could take you about 2 minutes if the book has an index. With an index, you just flip to the back, look under ‘N’, find Napoleon, see what pages they are, and you’re done.
When we think about what an index does, it’s trading effort now (because an index takes time to make) and storage space (because it takes up pages in the book) in return for much quicker lookups in the future. We can do the exact same thing with data on our computers.
Indexing used to be really popular in digital forensics. While it isn’t done as often anymore because it doesn’t scale well and can take a while to create, I still use it all the time when dealing with large datasets. Let me give you an example of how I use indexing with a large dataset.
One of the large data sets that I have an index for is my repository of historic WHOIS information – about 278 gigabytes worth that I use regularly. Searching through that can take some time. Indexes are only really good if the data is static. My historic WHOIS data is perfect for this – I may add new stuff to it, but the old stuff doesn’t go away or change. This is unlike monitoring info stealer logs, which can generate terabytes daily. An index isn’t really going to help you if the data is that dynamic.
For indexing my 278 gigs of historic WHOIS data, I use a tool called Qgrep. It’s free, fantastic, and open source. Qgrep works very similar to the Linux utility grep if you’re familiar with that – it helps us find certain pieces of information. The difference is Qgrep also has the capability to make and utilize indexes, which can help speed up our searches quite a bit.
When you use Qgrep to create an index, by default it saves that index buried down in a user directory. If you like that, that’s fine, but personally, I don’t. I like to save my indexes somewhere easily accessible where I can see them. Even though you’re never touching the indexes manually – you may update it but you’re not going in there and modifying it yourself – I still don’t like potentially large files buried under my user profile. I prefer to have them somewhere I can see them.
The syntax for Qgrep is pretty straightforward when creating a new index. Instead of just telling it where we want it to index, we give it two file paths. The first one (#1) is where we want the index to be stored, with the last part of that path being the actual filename for our index files (#2). The second path we give it is the directory (and its subdirectories – it’s recursive) that we actually want it to index (#3).
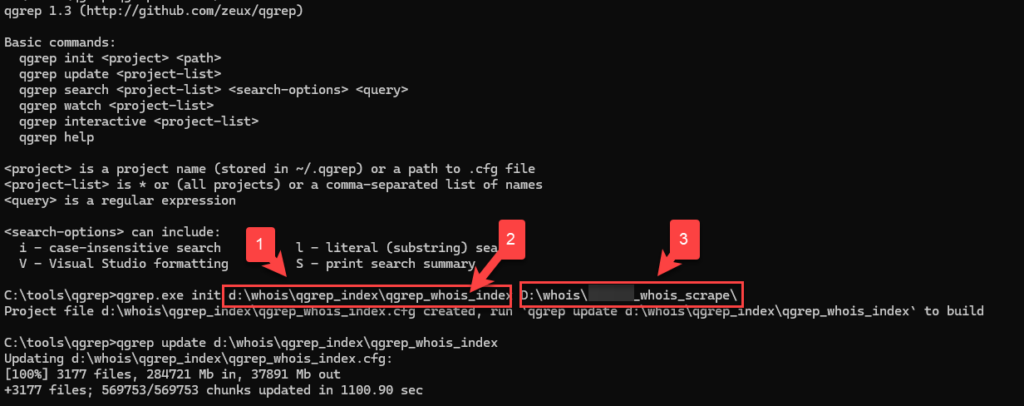
Qgrep can index very quickly. For instance, indexing my 278 gig of historic WHOIS data took about 18 minutes on my computer with an i9 processor. The index itself ended up being about 42 gigabytes in size – that’s pretty quick and the index size isn’t bad. Tomorrow we’ll do some tests to see how much quicker our searches are using our index compared to normal command line utilities.